
 kinectFusion
kinectFusion
第一篇基于RGB-D相机实时稠密三维重建的论文。
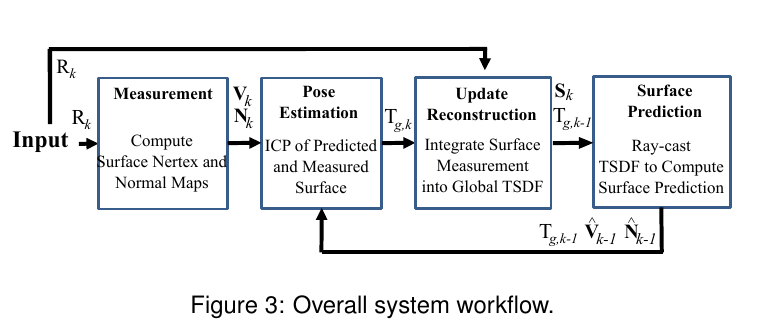
过程梳理:对于上一帧的最后,生成一个Surface Prediction,当前帧深度图输入,由深度图生成Surface Measurement,通过Surface Prediction和Surface Measurement使用icp进行配准估计位姿,更新和融合全局TSDF。
# 表面测量
通过当前原始的深度图生成分层稠密的顶点图和法向量图。
首先对当前帧的深度图进行双边滤波;
利用深度图信息生成当前帧的点云图;
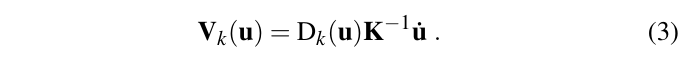
点云图中三个点确定一个平面,利用叉乘算出这个平面的法向量,并归一化。
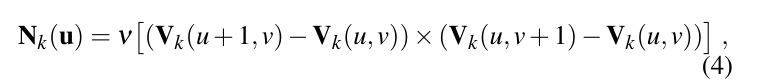
对深度图进行分层,最底层是原始的双边滤波深度图,每高一层,用块平均把分辨率降低一半,这里平均的深度是距离中心坐标不超过
。然后计算相应的法向量图。
# 表面更新
将当前帧生成的表面融合到全局模型中。
对于当前帧深度图,和当前位姿,建图就是通过TSDF融合增量的过程。TSDF模型如下简单介绍,
将要重建的场景放到这个大长方体中,每一个小正方体代表一个体素,每一个体素都有一个TSDF值,和一个权重w。
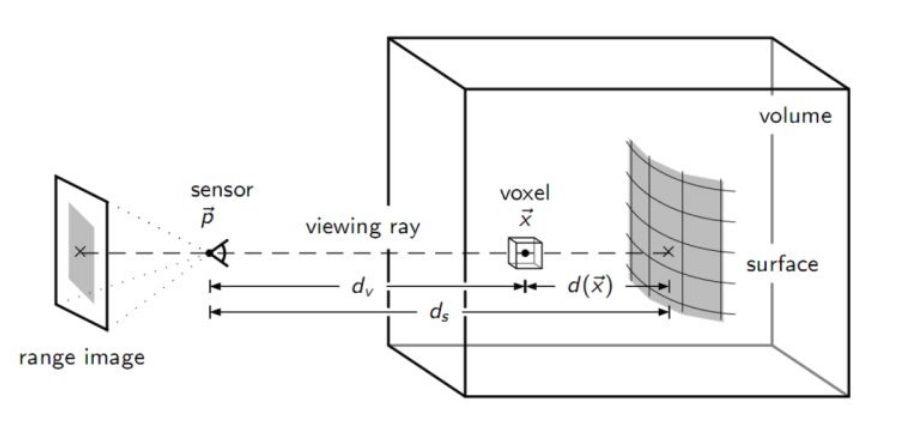
现在要做的就是,对计算每一个体素的TSDF值和权重,首先计算SDF等于相机到实际表面的距离减去相机到体素的距离,即体素到表面的距离。如果值为零或者接近零,则这个体素代表实际表面上的点。
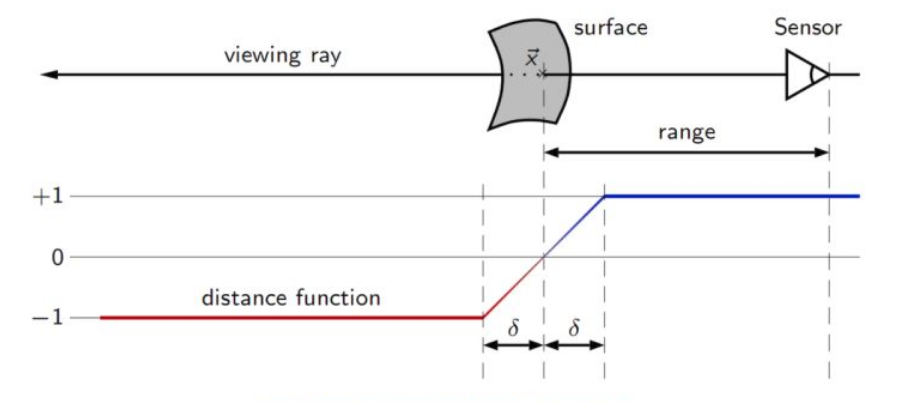
T为截断的意思,SDF值超出一定范围,就将其置正负1。
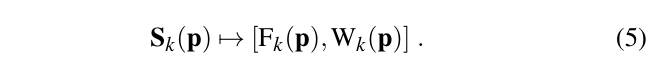
论文中每个体素p用距离F和权重W来表示。
深度传感器测量的深度假设有误差正负
论文中计算距离公式

解释如下

体素的权值为
融合公式

上面计算SDF值时用的深度值是原始深度图的值,而不是使用经过双边滤波后的。
# 表面预测
对当前帧生成一个表面。当前时刻的预测图是通过上一时刻构建完成的TSDF模型获得,对于知道当前时刻的位置,通过光线透射方法获得当前时刻相机能够观测的场景,(对当前时刻每个像素发出一条光线,方向是
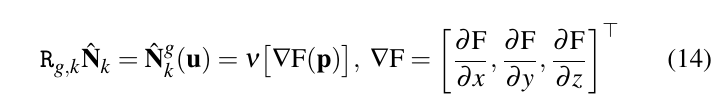
预测表面这一步完成一个顶点图(点云图),和对应的法向量。
# 位姿估计
对当前帧生成的测量表面与预测表面进行icp配准,估计当前帧的位姿。假设两帧之间的相对运动很小,利用上一帧的位姿作为当前帧的初始值,然后通过初始位姿进行投影,找到测量表面和预测表面之间的数据关联(有深度测量,坐标相近,法向量相近),然后进行点到面的icp。
习以为常的点到面icp误差项
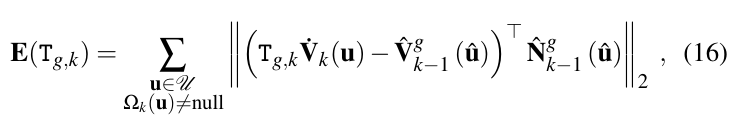
# 参考
https://ieeexplore.ieee.org/document/6162880
https://blog.csdn.net/fuxingyin/article/details/51417822
https://blog.csdn.net/qq_40213457/article/details/82383621?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164566967616780271931390%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164566967616780271931390&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-4-82383621.pc_search_result_cache&utm_term=tsdf&spm=1018.2226.3001.4187
https://zhuanlan.zhihu.com/p/35894630