Redis
Redis
# 缓存穿透
查询一个不存在的数据,MySQL查询不到数据,那也不会写入缓存中,就会导致每次都查询数据库。
方案一: 缓存空数据
把空的数据也存入到缓存中,问题是,当之后数据库有这个数据后,缓存中还是缓存的空,那么就脏读。因为不能一有新数据就往缓存中添加。
方案二: 布隆过滤器
缓存预热过程中,初始化布隆过滤器。对于一个查询,如果查询到布隆过滤器中有数据,那么才进行后面的过程,若布隆过滤器中不存在,则直接返回。布隆过滤器判断数据存在,不代表Redis中数据真的存在。若不存在,那真不存在。对于新添加到Redis中的值,同时添加到布隆过滤器中。
# 缓存击穿
给一个key设置了过期时间,当key过期时,有大量请求访问这个key。
每一个请求来访问,都判断缓存中没有这个key,因为这时还没有一个线程请求结束。进而都进行访问数据库。
**方案一:**互斥锁
当某个线程想去访问数据库时,加互斥锁,然后查询数据库,把数据写入缓存。其它线程等待这个线程释放锁,然后去缓存中获取数据。
**方案二:**逻辑过期
把数据设置为不过期,如果查询缓存发现数据逻辑过期,那就获取互斥锁,新开一个线程去数据库把数据写入缓存(写完后新线程释放锁,锁传递?),当前线程就返回过期数据。如果其它线程
# 缓存雪崩
同一时间段有大量的key过期,或者Redis服务宕机。
- 给不同的Key的TTL添加随机值
- 利用Redis集群,哨兵模式,集群模式
- 加降级和限流策略,Nginx,gateway
- 加多级缓存,Guava、Caffeine
# 双写一致
当修改了数据库的数据,同时更新缓存。
- 延迟双删
删除缓存-》修改数据库-》删除缓存
删除了一次缓存后,在中间过程有请求过来,又会重新写入缓存(脏数据),所以后面再删一次。最后一次删除时间不好把控
- 读写锁
当线程对某个数据获取到写锁,那么其它线程不能读写。
当线程获取了某个数据的读锁,那么其它线程可以进行读。
- 异步通知
保证数据的最终一致性
当有修改数据,写入数据库成功后,发布消息

- Cannal

# 持久化
- bgsave
开始时,主进程fork子进程,将内存的数据写入RDB文件到本地。
当子进程执行写操作时,会将数据拷贝一份,执行写操作。
- RDB
数据快照文件
- AOF
记录Redis中每一个写命令。
# 数据过期策略
**惰性删除:**设置key过期后,不去管它,等查询到这个数据了,发现过期,再删掉。
**定期删除:**每隔一段时间,对key进行检查,删除里面过期的key。
# 数据淘汰策略
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:对全体key ,随机进行淘汰。
- volatile-random:对设置了TTL的key ,随机进行淘汰。
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰
# Redis分布式锁
获取锁 SETNX key value EX 10
释放锁 DEL key
# Redisson
某个业务通过setnx设置变量后,当服务挂了,那么就没有del 该变量,导致其它业务不能setnx,通过设置超时时间,又不够优雅。
获取Redisson锁,其业务内Watch dog机制作为守护线程,定时为key自动续期。如果业务执行完毕,会删除这个key。如果业务中断了,那这个定时任务也不执行了,也就不会自动续期,到期后自动删除。
**可重入:**锁结构上存的字段是获取锁的线程,在一个线程内是共享的,同时存储锁获取次数。
存在主从数据一致性问题,在一个主节点上SETNX,这时主节点挂了,然后有新的主节点,这时其它应用也可以SETNX。
RedLock:在多个实例上创建同一个锁,如果超过半数的实例上SETNX成功,那么客户端获取锁成功。
# 主从复制
搭建主从集群,实现读写分离

全量同步:
先判断主从是否是一个数据集,不是一个数据集,需要进行全量同步,主节点执行bgsave,生成RDB,发送RDB文件给从节点。
增量同步:
记录偏移量,随后的主从是进行增量同步,主节点将repl_baklog大于偏移量的部分的命令,发送给从节点。
# 哨兵
实现主从集群的自动故障恢复。
Sentinel会心跳检测节点是否活着,如果master故障了,会从slave中选一个作为master,并通知客户端发生集群故障转移。
主观下线:某个Sentinel节点检测不到某个Redis实例。
客观下线:超过指定数量的Sentinel节点检测不到某个Redis实例。
# 集群脑裂
主节点、从节点和Sentinel处于不同的网络分区,然后检测不到master,就选举了一个新的master。但实际上就存在了两个master。网络恢复后,老的主节点降为从节点,再从新的master同步数据,导致数据丢失。
解决:减少一下从节点数量,缩短主从同步时间间隔。(没有从根本上解决)
# 分片集群
解决海量数据存储问题,高并发写的问题。
- 集群中有多个master,每个master保存不同的数据
- 每个master又有多个slave节点
- master ping健康状态。
分片集群有16384个哈希槽,每个key通过CRC16校验后对16384取模,决定存放在哪个槽,集群每个节点负责一部分hash槽。

# Redis为什么快
- 纯内存操作
- 采用单线程,避免不必要的上下文切换
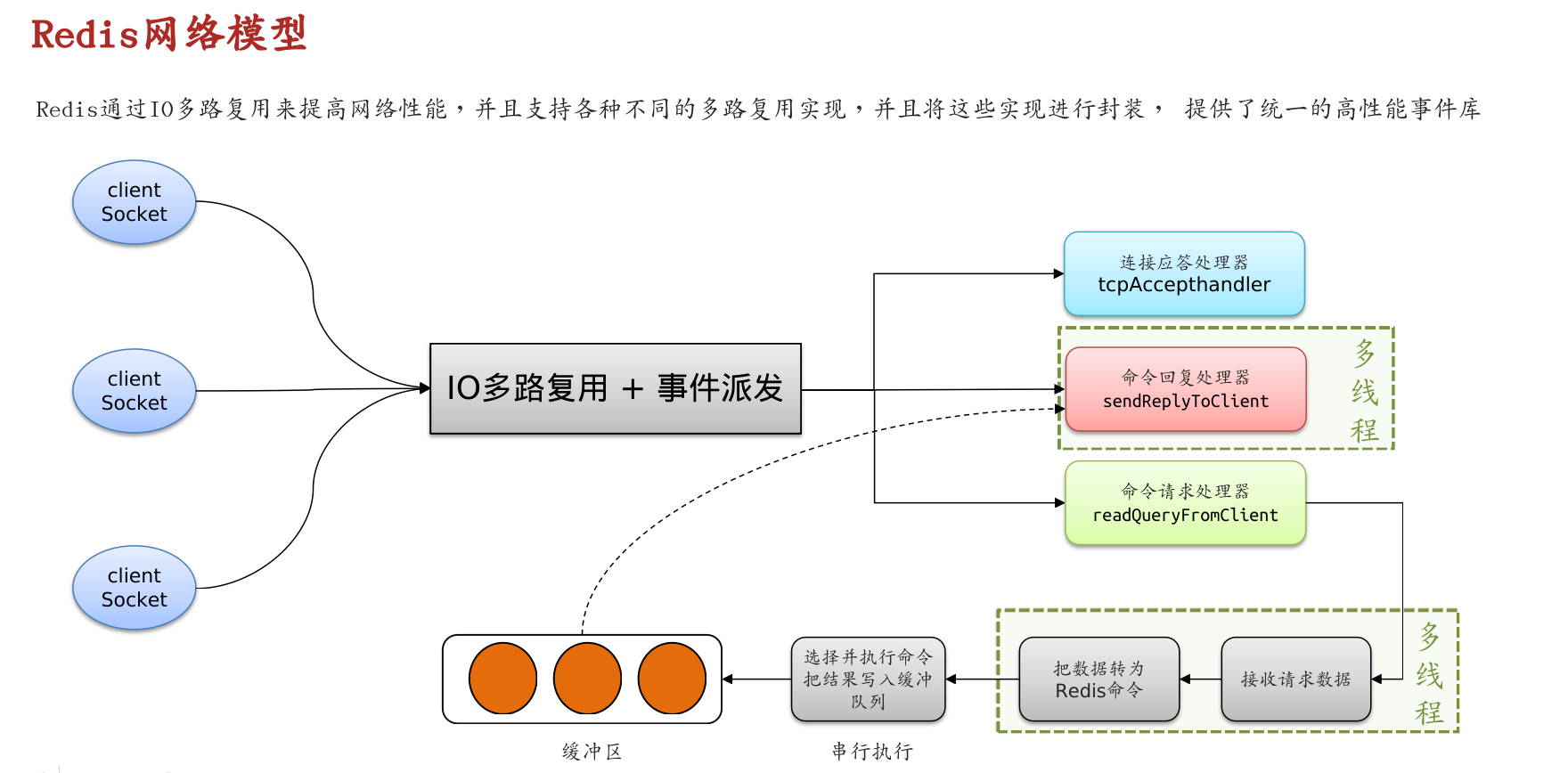
- I/O多路复用
# I/O多路复用

对于某个客户端,调用阻塞select,内核监听Socket集合,任一一个socket数据就绪,将会唤起select。随后客户端调用对应的Socket的recvfrom方法获取数据。
select和poll只会通知用户进程有Socket就绪。
epoll通知用户进程哪些Socket就绪。