
 限流
限流
# 雪崩问题

微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
解决雪崩问题的常见方式:
- 超时处理:设定超时时间,请求超过一定时间没有响应就返回错误消息,不会无休止等待。(缓解作用)

- 线程隔离:每一个服务弄一个线程池,固定每一个服务的请求数,这样一个服务挂了,不会导致其它服务的资源也耗尽。

- 降级熔断:断路器统计某一个服务中的远程调用异常的比例,如果超过一个阈值,那么就停止它对其它服务进行远程调用。

- 流量控制:从源头控制流量到这个服务,预防服务一次性接收的请求过多。

总结
限流是对服务的保护,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。是一种预防措施。
超时处理、线程隔离、降级熔断是在部分服务故障时,将故障控制在一定范围,避免雪崩。是一种补救措施。
# Sentinel
隔离策略:
线程池隔离:对每一个服务创建单独一个线程池
信号量隔离:规定每个服务最大有几个线程,然后再去同一个线程池里拿线程。
一些感念

单机阈值:设置某个资源请求的QPS最大值,超过部分返回流量控制错误。
流控模式:
- 直接
- 关联:当/write资源访问量触发阈值时,就会对/read资源限流,避免影响/write资源。(优先处理/write)

- 链路:
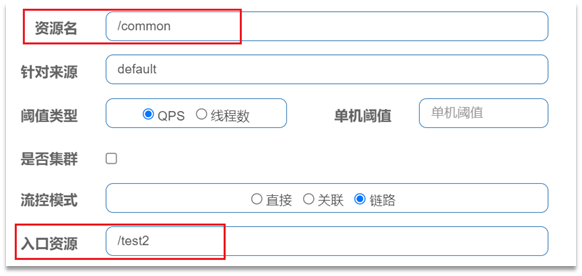
例如有两条请求链路:
/test1 --> /common
/test2 --> /common
如果只希望统计从/test2进入到/common的请求,则可以这样配置:
流控效果:
- 快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常。默认的处理方式。
- warm up:预热模式,同上,但阈值会动态变化,从一个较小值逐渐增加到最大阈值。
- 排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长。QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过2000ms的请求会被拒绝并抛出异常。
热点参数限流:可能部分商品是热点商品,例如秒杀商品,我们希望这部分商品的QPS限制与其它商品不一样,高一些。
# 隔离和降级
# 降级
- feignclient远程调用失败降级
- 编写降级方法,实现
FallbackFactory接口,并给spring容器管理 - 在feign接口中的方法头添加上
fallbackFactory
# 隔离
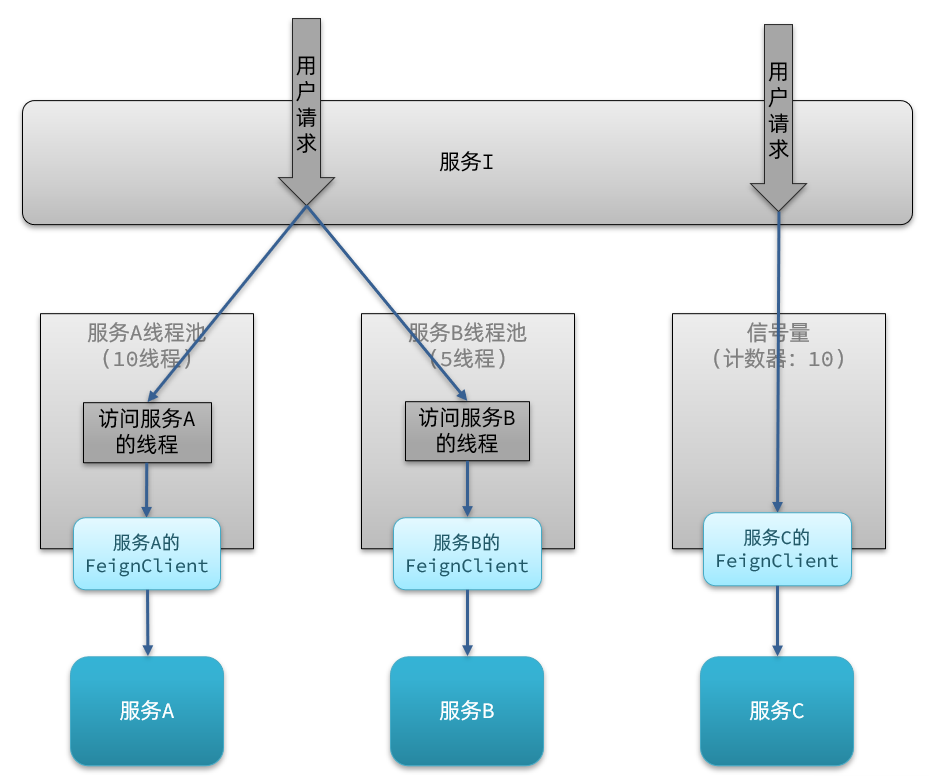
线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果。
信号量隔离:不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
sentinel中可以配置根据线程数来控制请求。
# 熔断降级
- 断路器状态

- 慢调用:RT超过500ms的调用是慢调用,统计最近10000ms内的请求,如果请求量超过10次,并且慢调用比例不低于0.5,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。

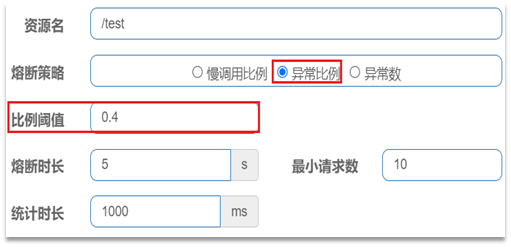
- 异常比例:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于0.4,则触发熔断。
- 异常数:统计最近1000ms内的请求,如果请求量超过10次,并且异常数不低于2次,则触发熔断。

- 授权规则:对调用方的来源做控制,有白名单和黑名单两种方式。我们允许请求从gateway到order-service,不允许浏览器访问order-service,那么白名单中就要填写网关的来源名称(origin)。

- 规则持久化:控制台将配置规则推送到远程配置中心,例如Nacos。Sentinel客户端监听Nacos,获取配置变更的推送消息,完成本地配置更新。
